2 min to read
Handwritten digit recognition

Teaching machines to recognize hand written digits.
Data Description:
MNIST (“Modified National Institute of Standards and Technology”) is the de facto “hello world” dataset of computer vision. Since its release in 1999, this classic dataset of handwritten images has served as the basis for benchmarking classification algorithms. As new machine learning techniques emerge, MNIST remains a reliable resource for researchers and learners alike.
The goal is to correctly identify digits from a dataset of tens of thousands of handwritten images.
Introduction:
This is a 5 layered Convolutional Neural Network trained on MNIST dataset. I’ve used Keras framework for building the Neural Net architecture. I was able to achieve a public score of 99.5% categorization accuracy on the unseen data with a rank of 426/2255 which in turn is among Top 6% in the Public Leaderboard. [Update: the rank is from date Jun 19, 2017 21:33, current rank may differ]
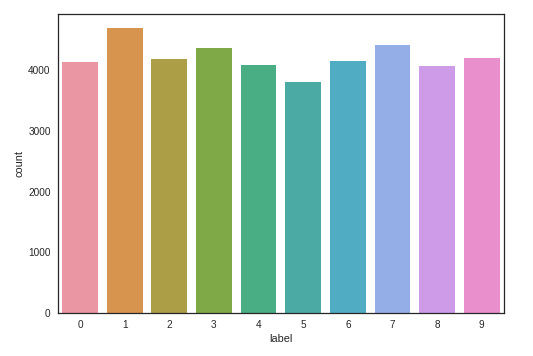
Number of training examples per digit:
CNN Model Architecture
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 28, 28, 32) 832
_________________________________________________________________
conv2d_2 (Conv2D) (None, 28, 28, 32) 25632
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 14, 14, 32) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 14, 14, 32) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 14, 14, 64) 18496
_________________________________________________________________
conv2d_4 (Conv2D) (None, 14, 14, 64) 36928
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 7, 7, 64) 0
_________________________________________________________________
dropout_2 (Dropout) (None, 7, 7, 64) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 3136) 0
_________________________________________________________________
dense_1 (Dense) (None, 256) 803072
_________________________________________________________________
dropout_3 (Dropout) (None, 256) 0
_________________________________________________________________
dense_2 (Dense) (None, 10) 2570
=================================================================
Total params: 887,530
Trainable params: 887,530
Non-trainable params: 0
_________________________________________________________________
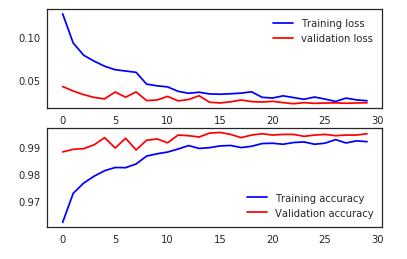
Training loss vs Validation loss & Training accuracy vs Validation accuracy
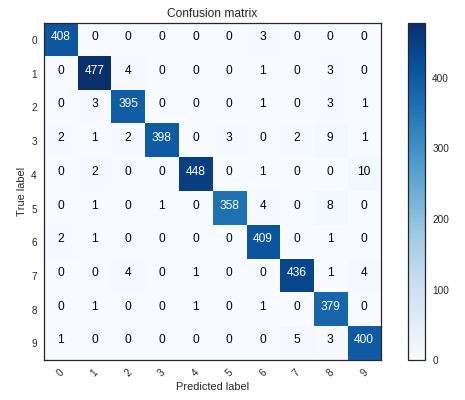
Confusion Matrix
Some examples

Data Source: Kaggle
Check out the whole project on GitHub
If you liked this project, please consider buying me a coffee

Comments